










By Nick Blamey
How Test Automation combined with Batch Testing and Defect Analysis at the Database level can optimize your DevOps process.
With full end-to-end testing through the User Interface already established at many organisations, the challenge of “shifting-defects-left” in legacy applications still exists. Service Virtualisation is an option to test multi-tier applications with a legacy core but this level of abstraction can often leave a substantial body of mission critical application logic unchecked, presenting a significant risk to your project. This article explores a several options available to resolve these challenges.
A thought- inspiring blog by ARCAD’s Director of Northern European operations, Nick Blamey
Summary
- The business problem
- A different paradigm for testing and locating defects with Legacy Systems
- Problems Associated with Batch Processing
- Testing a multi-tier application with Dependencies between legacy IBM i and new “front-end” components: what are your options?
- UI Testing and Test Automation: Most of it is below the surface!
The business problem
Time-to-market and the associated benefits of providing rapid feedback to developers are a key part of any DevOps strategy. Standard approaches of catching defects which occur at the UI layer – while important – still fail to eliminate a number of key challenges organisations face in particular in the following situations:
- Where significant and mission critical application functionality resides in complex Batch processes
- Where a number of legacy applications are involved e.g. on the IBM i / Mainframe which tends to result in a multi-speed development approach and complex defect triage effort between new application development team and the legacy core teams
- When isolating any defects directly within the Database and understanding the impact of changes to application program have a direct effect on the Database level functionality
- Where the demand for obfuscation and anonymisation of Test Data are part of the compliance process
Most organisations are embracing End to End UI Testing automation using a combination of the following solutions:
- HCL OneTest
- Tricentis TOSCA
- Worksoft Certify
- Rational Functional Tester
- Selenium
- Mobile Application Testing Tools e.g. Eggplant, Perfecto Mobile etc.
Each Test Automation solution has advantages and unique capabilities to support different Testing Approaches but they all lack the ability to test, locate (triage) and fix complex legacy application errors buried deep in the legacy applications themselves on the IBM i (AS/400).
A different paradigm for testing and locating defects with Legacy Systems
We can analyse the 3 main challenges and potential bottlenecks to the process which cannot be eliminated by these standard tools as follows:
- Batch Testing: Batch programs tend to be large scale mission critical application functionality embedded in batch processes combined with…
- Complex Database and IBM i Spool file defects buried in the Database layer which results in exceptionally long debug cycles for developers to find and locate defects..
- Test Data anonymisation challenges including continue Test Environment refresh to cope with GDPR and other compliance requirements
From ARCAD’s experience with some of the largest Legacy application estates, these challenges are becoming more and more complex to solve. The rest of this document will explain both why these challenges have a potential to limit the speed of your DevOps process but also how you can solve these challenges using ARCAD solutions.
Why are Batch Testing, Database Level Testing and Defect Triage each a major potential challenge and potential bottleneck to your development process?
- There are many solutions to solve these problems but each one involves manual coding of a bespoke solution to fix e.g. Batch Testing with the inherent risk of maintenance of “roll your own software” in terms of both the knowledge required to create your own Batch Testing solutions but also the business risk of ongoing maintenance
- Debugging any problems around Database level defects through the User Interface tends to burn massive development effort with the “triage of defects” embedded in multiple components being one of the key limiters of achievement of DevOps aspirations
- Message Queue style Spool file defects tend to cause some of the most serious defects in Legacy IBM i applications which further exacerbate the problems.
The goal of the remainder of this article is to explain in detail both the options at your organisation’s disposal to resolve these problems, and the solutions available from ARCAD proven by multiple software development teams, typically developing on a combination of IBM i legacy applications and the front-end apps leveraging the business logic contained within the legacy.
“Unpicking the Spaghetti of Batch processes”: Common Defects from Batch are easily diagnosable in the Spools and Database
The most common defects created by Batch programs tend to be created by simple mistakes in the configuration of Spool and Database commands. However simple it is to “fall foul” of these simple but potentially “showstopping” defects, the effort most teams tend to expend in trying to reproduce them and fix them can massively limit the ability for a development team to make risk-free changes to applications where Batch, Spool and database edits form a crucial part of their functionality.
Typical Testing Challenges with Spool, Database and Batch can be classified as follows:
- Requirement to hand-script a batch execution, and then further to write complex database code to verify that on completion of the batch processes, the correct tables have been updated accurately in the test database.
- The need to confirm that application functionality remains the same when changes are made to the code which interacts with Spool and Database components. Programmers need to be able to understand, debug, fix and re-test complex functionality which touches these components. A typical example would be where the developer needs to check that a large table of data is “read in its entirety”. If this functionality contained a defect then an application could produce a serious defect if the range of data was limited to a subset of the data which can cause both application functionality defects but also impact the performance of the application.
- Creation of an application specific testing framework with the inherent challenges of: hand coding error reporting functionality, test data refresh capabilities with the associated risk that the functionality of the Test Harness / Framework becomes more complex than the application code itself.
- The creation of error handling functionality which runs the risk of either displaying too many additional errors (some of which can result in errors in the Test Framework / Harness itself) and then creating even more work for developers in fixing them: defect overload but even worse the risk that serious errors are then deemed to be part of the Test Harness which are then ignored.
- Finally, the developer spending a great deal of time creating end-to-end tests with the associated documentation when a simple “recording” of how the users “actually” use the application would uncover a true and up-to-date view of the end-to-end tests which real users actually perform during their day to day usage of the application in production.
- Further the ability to perform Test Coverage metrics for Compliance reasons (to show that all the application functionality which has changed in the latest iteration) has been fully tested and that 100% code change coverage has been achieved. The ability to exploit the functionality of the Rational Developer for i (RDi) IDE will become more and more important as the DevOps cycle accelerates and more and more application versions are pushed into production.
These challenges above can all be handled seamlessly and most importantly with zero programming effort using the ARCAD-Verifier Test Automation solution, described below.
DevOps requires Build Verification Testing (BVT) / Smoke Testing
To ensure that a “testable” application is passed to the QA team from development in rapid iterations many organisations create a suite of Build Verification Tests (BVT). This process is key to ensuring that defect tracking systems are not filled with “test environment unavailable” or “incorrect data in Test Environment” defects.
Smoke testing covers most of the major functions of the software but none of them in depth. The result of this test is used to decide whether to proceed with further testing. If the smoke test passes, go ahead with further testing. If it fails, halt further tests and ask for a new build with the required fixes. If an application is badly broken, detailed testing might be a waste of time and effort.
The risk to any organisation of NOT having a BVT / Smoke Testing process is a large number of additional defects being created, each of which need to be analysed, triaged and fixed even when the defects are actually NOT software problems but rather Build Verification problems.
The effect of lack of Build Verification Testing is that a typical defect classification Report Tends to show many defects classified as “cannot reproduce error” or “test environment issue” or “test data issue” thereby slowing down development time but also distorting the ability for Software development organisations and application stakeholders to make rational decisions about the severity of particular defects.
Problems Associated with Batch Processing
The biggest challenges facing IBM i developers is that a “batch” workload by definition interacts with and impacts many components / programs and is often critical functionality that runs “headless” i.e. in an unconstrained mode.
A batch job will always complete its workload in the shortest possible “low application usage” window to eliminate the impact on application performance. The challenge this creates for IBM i developers is that a batch process attempts to override any other workload running simultaneously because it will always prioritize execution speed over any resource balancing on the hardware it is running on. The only time a Batch process will lose priority is when its execution is limited by a system bottleneck i.e. normally the smallest Data Flow point in the application.
Because of the two problems detailed above, many developers look to perform scheduled batch jobs out of hours which can limit the functionality of the application whilst users wait for the “overnight batch jobs” to complete before performing their work.
Modern DevOps development teams on the IBM i have to constantly manage the following challenge: the need for batch jobs to execute quickly due to their “mission criticality” of their work and the reliance of other application functionality on their completion.
Batch testing: make sure that your batch performance does not cause defects downstream by non-completion
Whilst many Batch applications on the legacy were written many years ago, by definition they often contain mission critical functionality constituting a major part of your application’s value. For these reasons the continual enhancement of batch functionality presents a number of challenges:
- There is a need for a DevOps solution to continually maintain the batch processes and associated Test Data and Test Environments.
- Batch processes tend to require a deep understanding of the architecture of the entire application.
- Batch processes tend to run in parallel meaning a failure in one batch process can result in exceptionally complex defect triage and fixes.
- Batch processes can cause disruption to the performance and functionality of an application if they run incorrectly.
For this reason, many organisations attempt to create a totally seamless process for Batch Process change/commit and then attempt to make these changes available to the Test LPAR. The effort involved in trying to perform Batch testing can then become punitive with the maintenance of the batch test process over-consuming development team resources and causing project delays.
Why direct your testing efforts onto Batch and Database level testing?
- Defects in Batch and database are the most difficult to find, most costly and most risky to transfer into live production without end-to-end testing
- Batch processes by definition are high-risk, typically a culmination of a number of transactions each creating value and each with a high potential impact. Manual rework of Batch processes in production tends to be the most difficult and expensive to fix.
How severe can Batch defects become?
Because of the complexity of testing Batch and their specific data and test environment requirements, batch failures have led to some of the most publicized incidents ever witnessed. A particularly high-profile incident was the prolonged downtime at RBS in 2015 – and a similar episode in 2012 – caused by batch process failures at the bank impacting hundreds of thousands of customers.
Batch defects also tend to be neglected by many “end-to-end” test processes, but due to their mission criticality, their requirement to run and complete in a specific application usage window (normally when an application usage is more limited) and potential impact on the usability and performance of the application, certain defects in batch functions can “slip through the net” and reach production with disastrous consequences.
A particular concern with batch testing is Performance. If a batch process runs daily on close of business and application response time suffers, then batch performance is a factor to consider when creating a risk-based testing process.
Testing a multi-tier application with Dependencies between legacy IBM i and new “front-end” components: what are your options?
The table below details the options available and benefits and pitfalls of each option, based on ARCAD customer feedback.
| Options Available | Advantages | Risks | Challenges common to each option |
| Don’t bother: monitor batches in production. | Zero effort in development: Production defects becomes a testing and then operations problem, shifting it away from the root-cause which is developer defects. | Defects occurring tend to be discovered out-of-hours therefore lengthening resolution times, re-execution of batch doesn’t fix the problem: defect becomes worse. |
|
| Test at the UI and stub out legacy systems. |
|
|
|
| Hand script Batch execution and then write specific code to verify correct update to and contents of the test database. | A highly configurable “self-written” solution controlled and maintained by your in-house development team. |
|
|
| ARCAD-Verifier |
|
Minimal but requires investment in ARCAD: normally accompanied by compelling business case based on the “shift left” ROI Metrics which ARCAD can supply. |
|
Additional Value of the ARCAD-Verifier Solution
ARCAD-Verifier is unique on the market in its ability to handle batch processes. The additional value delivers your organisation a seamlessly integrated solution for eliminating the testing bottlenecks in your process and ensuring a “frictionless” DevOps CI/CD pipeline.
ARCAD-Verifier can check a process was executed to completion by automatically running tests on the batch process, re-setting the test data and then re-iterating the test to check for defects.
EDI and Batch-specific capabilities:
ARCAD can seamlessly simulate the insertion of files into any database running on the IBM i connected to the database(s) of external companies or organizations.
By simple creation of batch tests through ARCAD-Verifier scenario recording, test data refresh and rollback, development teams can dramatically can improve the time wasted in the debug process whilst directing the correct development team to the exact “root cause” of the defect.
Then by using ARCAD-Observer developers are able to more rapidly understand the application structure and cross-reference dependencies, adding value to the Development Effort when attempting to isolate and debug complex batch process defects.
Just as any IBM i application development, batch-based logic also requires a seamless development cycle. However, in the context of batch, the need for developers to rapidly perform Impact Analysis and identify Dependencies between application components and batch file output becomes even more important. ARCAD for DevOps offers additional capabilities to further eliminate these potential bottlenecks to the development, testing, debug and re-deployment of Batch processes on the IBM i.
Build Verification Testing (BVT) easily automates rapid developer feedback and eliminates defect triage challenges.
Modern development processes and DevOps requires Smoke Testing to be executed rapidly against each build once a developer commits code and deploys to the test environments.
UI Testing and Test Automation: Most of it is below the surface!
Many modern development teams have traditionally relied on the creation of Functional Tests and Load tests which focus on the user interface (UI). With Legacy applications, a significant proportion of the application functionality is buried deep in the IT infrastructure and hence the associated risks increase and the defects uncovered become especially expensive to locate and triage.
Expensive defects are more likely to arise when the changes in batch processes, spool files, Database updates occur deep within the IBM i application structure.
The limitations of functional testing
Most organizations perform functional testing of their applications through the UI, required for compliance reasons. However, like black box testing, since each and every defect needs to be diagnosed from the UI, this approach brings little information to help developers to actually fix problems. The result is typically a constant stream of defects classified as:
- cannot reproduce the issue:
- test environment not set up correctly
- require more information
EACH OF THESE are: especially complex with Batch processes and Test Environment state issues
With poor information for developers, the challenges are pushed downstream. Projects face delays due to lengthy code understanding and a sub-optimal debugging approach. This severely limits the ability for any IBM i development team to maintain the “speed of delivery” required for meeting their DevOps targets.
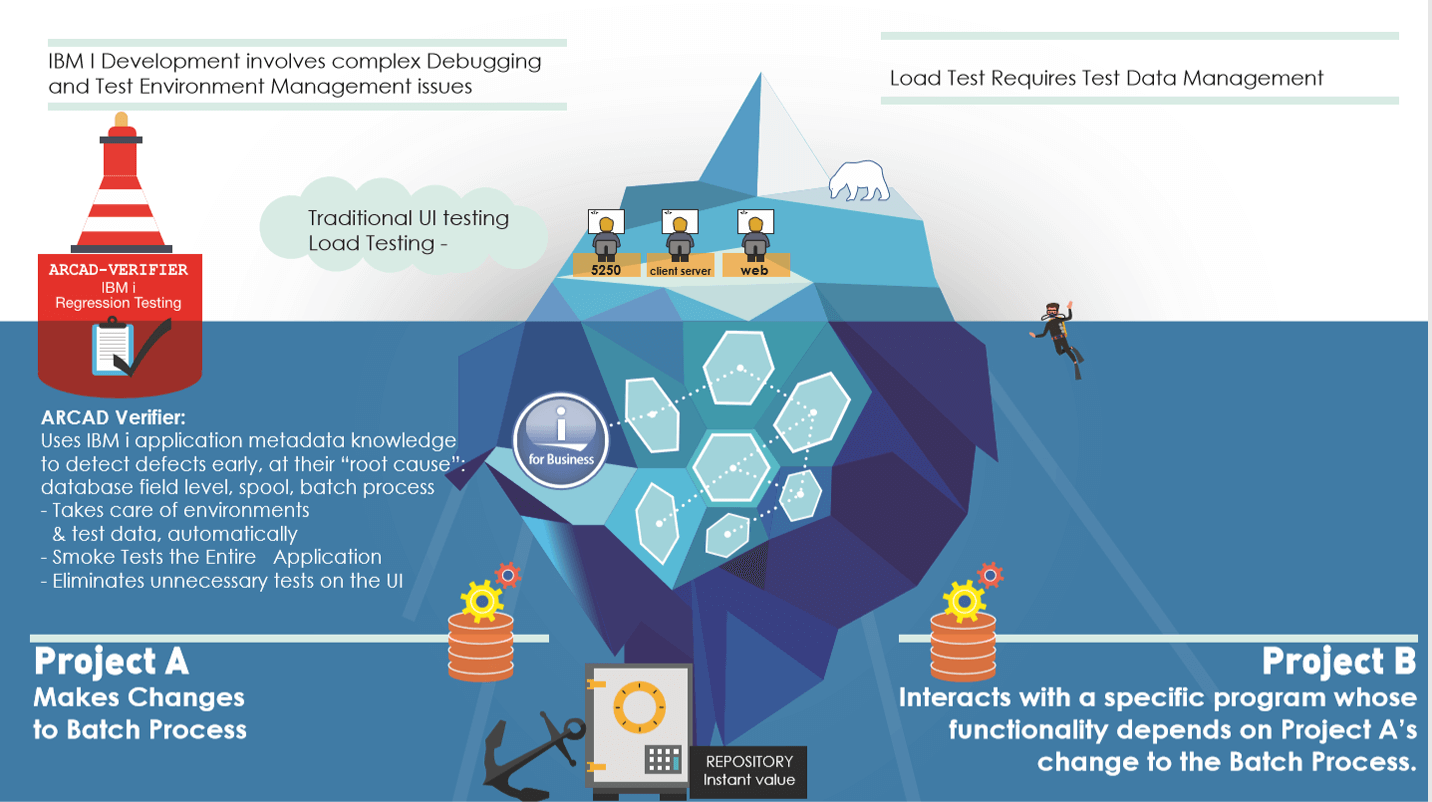
The diagram above illustrates a typical “complex” defect which can result from a change to a spool file, a batch process impacting other programs running on the IBM i and associated integration points with 3rd party components and other teams not associated with the IBM i.
Many organisations try to eliminate this problem by re-focusing their efforts on the hand-coding of functional tests at the UI level and hand-coding Batch tests and database-related checks, but this manual effort is costly and time-consuming. Further these “in-house” built batch, database and spool file tests can actually become (rather than resolve) the Testing Bottleneck due to ongoing maintenance of these assets.
Many clients now advocate the use of ARCAD tooling to specifically eliminate this potential risk to your frictionless DevOps process.
The limitations of UI Testing
The graphic below depicts the risks of focusing testing effort on the User Interface.
A reliance on UI-based testing leads to increased cost and project risk due to the challenges of isolating complex defects to their root cause deep within application components and architecture. In practice, with this method, developers typically take delivery of a defect report from a Defect Tracking system and then spend a high percentage of their time trying to localize and reproduce the defect. This causes the “time to resolution” to dramatically increase and results in a continual “reclassification of the defect” as the defect moves from team to team with each developer unable to resolve it. Defect Tracking Solutions like HP Octane / HP Quality Center collect metrics on these defects and tend to show an increase in the “average time to resolution” for most IBM i defects.
In addition, for development teams who are required to perform a full end-to-end test of their application for each and every component change, the continual process of debug, code change, re-deploy and re-test cycle can dramatically increase testing effort and cause project delays.

Getting under the bonnet of your Database to trap defects
If we think of any application as a motorised vehicle and the data as the Fuel which powers the vehicle then a large proportion of any testing effort needs to be on the “flow” of the fuel (i.e. DATA) through the application itself.
If an engine stopped working whilst on the race track, the engineer would of course be interested in areas of testing which focused on blockages in the fuel flow. They would diagnose the problem directly in the Engine looking for the blockage.
No engineer would try to look at the vehicle’s dashboard (i.e. User Interface in software terms) to understand a fuel blockage in the Engine.
Using this analogy in Software with Legacy applications, Software engineers should direct their efforts to the flow of data into databases and then into the application logic and this presents the following challenges to the Testing Process for legacy applications:
- Firstly, test data management: Nothing is more volatile, difficult to reinitialize and difficult to compare than test data,
- Secondly, scenario maintenance: Scenario creation is not everything. They must be then maintained in full synchronisation with the application versioning itself.
ARCAD Verifier delivers Optimization of your Testing Process
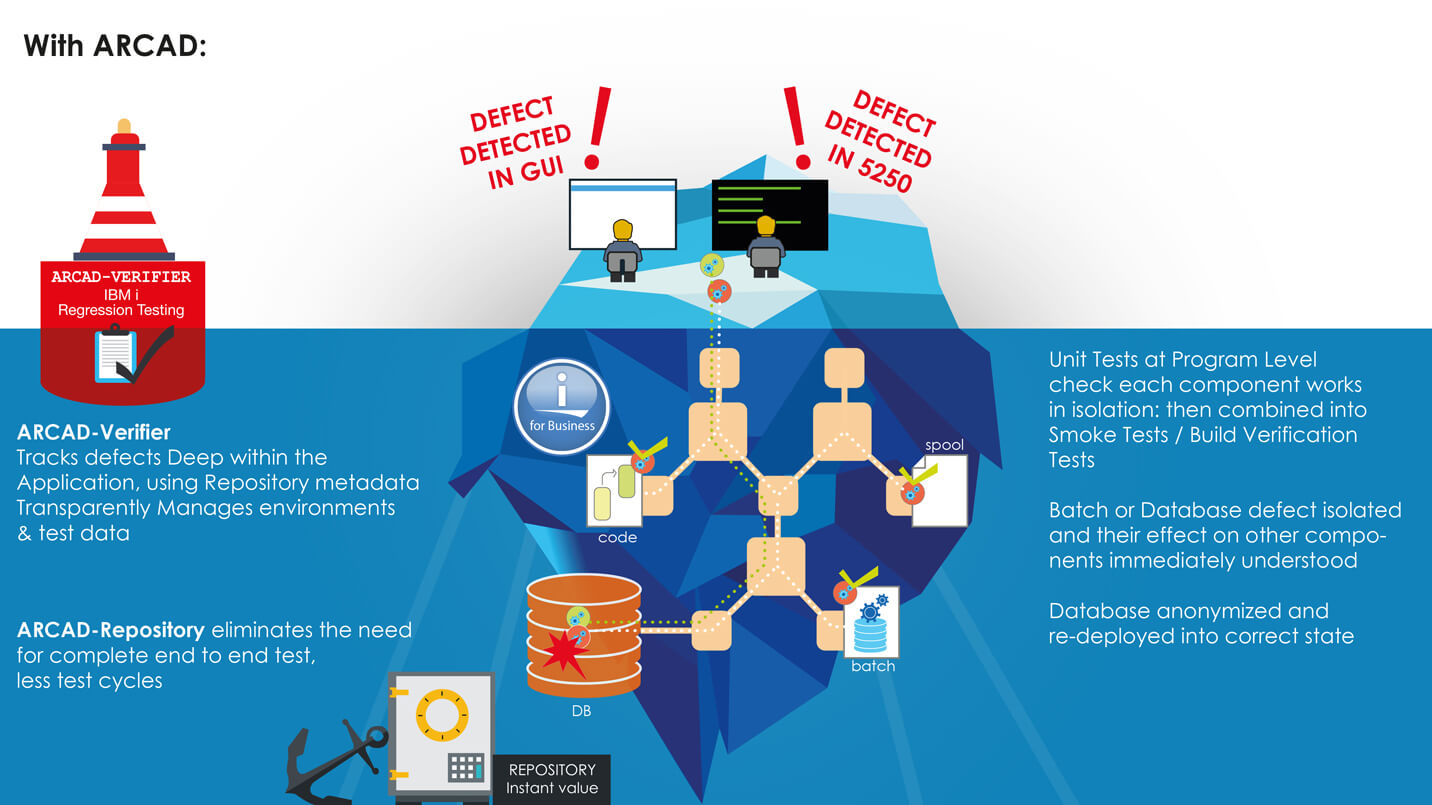
The diagram below explains the additional value which ARCAD can deliver to your testing process with no additional effort. As developers create Unit Tests on individual programs and functional tests at the green-screen or UI layer to check their work, the combined suite of “assets” can be converted into a suite or campaign of Regression Tests for execution against each and every version of the application following compilation and automatic deployment to your testing LPAR.
In addition, ARCAD Verifier can “mine” the data stored in your ARCAD repository to limit the number of end-to-end tests required – saving substantial time and effort – by only needing to execute the tests which are impacted by changes to the individual programs.

With ARCAD Verifier, the value of the application metadata stored in the ARCAD repository about your specific code base ensures that the number of tests to be run after each code change is limited to only those impacted by that change. Defects are diagnosed back to their “root cause” in individual components, and application changes can be re-compiled, re-deployed and re-tested at the “touch of a button” delivering a frictionless DevOps CI / CD pipeline.
Finally ARCAD Verifier fully integrates into Rational Developer for i (RDi) and the Test Coverage capability to create a fully compliant documented code coverage audit process with zero effort. Tests at the Spool, Batch or Database level are created automatically, and the precise origin of defects is isolated to deliver a fully optimized “shift left” of defects which can form an integral part of any organisations “continuous improvement” process.
ARCAD-Verifier: “Under the bonnet” defect triage spool file debug and data debug
Continuous Test as part of an automated CI/CD pipeline
ARCAD-Verifier can be integrated into Jenkins via plugins. In the framework of setting up continuous testing processes, Jenkins can steer performance of ARCAD-Verifier scenarios and the delivery of comparison reports. ARCAD-Verifier can also be integrated into most non-regression testing (NRT) tools on the market, in which case it supplements the reinitialization and comparison part of test data.
ARCAD Testing solutions
ARCAD The graphic below highlights the capabilities ARCAD offer for testing optimisation.

ARCAD Verifier and ARCAD for DevOps can take packages of applications through the development cycle and deploy them into the test environments on the IBM i LPARs in a seamless cycle. Tests on all components can be executed as described above isolating defects at the Database, Batch, 5250 UI, Spool and cross-reference layers with minimal effort. Any packages which pass their quality gate tests can then move seamlessly into Production.
DOT Anonymizer from ARCAD provides anonymization – or masking – of production data mined from the Production LPAR to deliver a secure, flexible and GDPR-compliant Testing solution. ARCAD for DevOps then delivers anonymized data to the test environments for use by testing teams, whilst maintaining the “homonymity” of the application data so that “edge case” testing can be performed in order to maximize the number of defects discovered. Results are then pushed automatically into your enterprise defect tracking/ticketing system, such as Jira, HP Quality Center, etc.
Read more about the business value of continuous testing for optimization of application debugging on IBM i in our last blog.
Recommended Next Steps:
An Audit of your current IBM i Testing process is an excellent starting point to your journey to a quality DevOps implementation.
To find out more about how ARCAD solutions can optimize your Testing Process, please contact your Sales Representative by emailing:
Further reading:
Definition of BVT and Smoke Testing:
https://www.softwaretestinghelp.com/bvt-build-verification-testing-process/
Shift Left Testing definition:

REQUEST A DEMO
Let’s talk about your project!
Speak with an expert